clamp / median / range
2025-07-02 02:45https://dotat.at/@/2025-07-02-cmp.html
Here are a few tangentially-related ideas vaguely near the theme of comparison operators.
( Read more... )
https://dotat.at/@/2025-07-02-cmp.html
Here are a few tangentially-related ideas vaguely near the theme of comparison operators.
( Read more... )
https://dotat.at/@/2025-06-28-boulder.html
Here's a story from nearly 10 years ago.
( Read more... )
After I found some issues with my benchmark which invalidated my previous results, I have substantially revised my previous blog entry. There are two main differences:
A proper baseline revealed that my amd64 numbers were nonsense because I wasn’t fencing enough, and after tearing my hair out and eventually fixing that I found that the bithack conversion is one or two cycles faster.
A newer compiler can radically improve the multiply conversion on arm64 so it’s the same speed as the bithack conversion; I've added some source and assembly snippets to the blog post to highlight how nice arm64 is compared to amd64 for this task.
https://dotat.at/@/2025-06-08-floats.html
A couple of years ago I wrote about random floating point numbers. In that article I was mainly concerned about how neat the code is, and I didn't pay attention to its performance.
Recently, a comment from Oliver Hunt and a blog post from
Alisa Sireneva prompted me to wonder if I made an
unwarranted assumption. So I wrote a little benchmark, which you can
find in pcg-dxsm.git.
(Note 2025-06-09: I've edited this post substantially after discovering some problems with the results.)
Briefly, there are two basic ways to convert a random integer to a floating point number between 0.0 and 1.0:
Use bit fiddling to construct an integer whose format matches a float between 1.0 and 2.0; this is the same span as the result but with a simpler exponent. Bitcast the integer to a float and subtract 1.0 to get the result.
Shift the integer down to the same range as the mantissa, convert to float, then multiply by a scaling factor that reduces it to the desired range. This produces one more bit of randomness than the bithacking conversion.
(There are other less basic ways.)
The double precision code for the two kinds of conversion is below. (Single precision is very similar so I'll leave it out.)
It's mostly as I expect, but there are a couple of ARM instructions that surprised me.
The bithack function looks like:
double bithack52(uint64_t u) {
u = ((uint64_t)(1023) << 52) | (u >> 12);
return(bitcast(double, u) - 1.0);
}
It translates fairly directly to amd64 like this:
bithack52:
shr rdi, 12
movabs rax, 0x3ff0000000000000
or rax, rdi
movq xmm0, rax
addsd xmm0, qword ptr [rip + .number]
ret
.number:
.quad 0xbff0000000000000
On arm64 the shift-and-or becomes one bfxil instruction (which is a
kind of bitfield move), and the constant -1.0 is encoded more
briefly. Very neat!
bithack52:
mov x8, #0x3ff0000000000000
fmov d0, #-1.00000000
bfxil x8, x0, #12, #52
fmov d1, x8
fadd d0, d1, d0
ret
The shift-convert-multiply function looks like this:
double multiply53(uint64_t u) {
return ((double)(u >> 11) * 0x1.0p-53);
}
It translates directly to amd64 like this:
multiply53:
shr rdi, 11
cvtsi2sd xmm0, rdi
mulsd xmm0, qword ptr [rip + .number]
ret
.number:
.quad 0x3ca0000000000000
GCC and earlier versions of Clang produce the following arm64 code, which is similar though it requires more faff to get the constant into the right register.
multiply53:
lsr x8, x0, #11
mov x9, #0x3ca0000000000000
ucvtf d0, x8
fmov d1, x9
fmul d0, d0, d1
ret
Recent versions of Clang produce this astonishingly brief two instruction translation: apparently you can convert fixed-point to floating point in one instruction, which gives us the power of two scale factor for free!
multiply53:
lsr x8, x0, #11
ucvtf d0, x8, #53
ret
My benchmark has 2 x 2 x 2 tests:
bithacking vs multiplying
32 bit vs 64 bit
sequential integers vs random integers
I ran the benchmark on my Apple M1 Pro and my AMD Ryzen 7950X.
These functions are very small and work entirely in registers so it has been tricky to measure them properly.
To prevent the compiler from inlining and optimizing the benchmark loop to nothing, the functions are compiled in a separate translation unit from the test harness. This is not enough to get plausible measurements because the CPU overlaps successive iterations of the loop, so we also use fence instructions.
On arm64, a single ISB (instruction stream barrier) in the loop is enough to get reasonable measurements.
I have not found an equivalent of ISB on amd64, so I'm using MFENCE. It isn't effective unless I pass the argument and return values via pointers (because it's a memory fence) and place MFENCE instructions just before reading the argument and just after writing the result.
In the table below, the leftmost column is the number of random bits; "old" is arm64 with older clang, "arm" is newer clang, "amd" is gcc.
The first line is a baseline do-nothing function, showing the overheads of the benchmark loop, function call, load argument, store return, and fences.
The upper half measures sequential numbers, the bottom half is random numbers. The times are nanoseconds per operation.
old arm amd
00 21.44 21.41 21.42
23 24.28 24.31 22.19
24 25.24 24.31 22.94
52 24.31 24.28 21.98
53 25.32 24.35 22.25
23 25.59 25.56 22.86
24 26.55 25.55 23.03
52 27.83 27.81 23.93
53 28.57 27.84 25.01
The times vary a little from run to run but the difference in speed of the various loops is reasonably consistent.
The numbers on arm64 are reasonably plausible. The most notable thing is that the "old" multiply conversion is about 3 or 4 clock cycles slower, but with a newer compiler that can eliminate the multiply, it's the same speed as the bithacking conversion.
On amd64 the multiply conversion is about 1 or 2 clock cycles slower than the bithacking conversion.
The folklore says that bithacking floats is faster than normal integer to float conversion, and my results generally agree with that, apart from on arm64 with a good compiler. It would be interesting to compare other CPUs to get a better idea of when the folklore is right or wrong -- or if any CPUs perform the other way round!
https://dotat.at/@/2025-06-01-bialetti.html
In hot weather I like to drink my coffee in an iced latte. To make it, I have a very large Bialetti Moka Express. Recently when I got it going again after a winter of disuse, it took me a couple of attempts to get the technique right again, so here are some notes as a reminder to my future self next year.
It's worth noting that I'm not fussy about my coffee: I usually drink pre-ground beans from the supermarket, with cream (in winter hot coffee) or milk and ice.
( Read more... )
https://dotat.at/@/2025-05-28-types.html
TIL (or this week-ish I learned) why big-sigma and big-pi turn up in the notation of dependent type theory.
( Read more... )
https://dotat.at/@/2025-05-13-if-is.html
About half a year ago I encountered a paper bombastically
titled "the ultimate conditional syntax". It has the
attractive goal of unifying pattern match with boolean if tests,
and its solution is in some ways very nice. But it seems
over-complicated to me, especially for something that's a basic
work-horse of programming.
I couldn't immediately see how to cut it down to manageable proportions, but recently I had an idea. I'll outline it under the "penultimate conditionals" heading below, after reviewing the UCS and explaining my motivation.
( Read more... )
https://dotat.at/@/2025-04-30-test.html
Recently, Alex Kladov wrote on the TigerBeetle blog about
swarm testing data structures. It's a neat post about
randomized testing with Zig. I wrote a comment with an idea that was
new to Alex ![]() matklad, so I'm reposing a longer version
here.
matklad, so I'm reposing a longer version
here.
( Read more... )
https://dotat.at/@/2025-03-30-hilite.html
I have added syntax highlighting to my blog using tree-sitter. Here are some notes about what I learned, with some complaining.
( Read more... )
https://dotat.at/@/2025-03-05-lemire-inline.html
Last year I wrote about inlining just the fast path of Lemire's
algorithm for nearly-divisionless unbiased bounded random
numbers. The idea was to reduce code bloat by eliminating lots
of copies of the random number generator in the rarely-executed slow
paths. However a simple split prevented the compiler from being able
to optimize cases like pcg32_rand(1 << n), so a lot of the blog post
was toying around with ways to mitigate this problem.
On Monday while procrastinating a different blog post, I realised that
it's possible to do better: there's a more general optimization which
gives us the 1 << n special case for free.
Lemire's algorithm has about 4 neat tricks:
use multiplication instead of division to reduce the output of a random number generator modulo some limit
eliminate the bias in (1) by (counterintuitively) looking at the lower digits
fun modular arithmetic to calculate the reject threshold for (2)
arrange the reject tests to avoid the slow division in (3) in most cases
The nearly-divisionless logic in (4) leads to two copies of the random number generator, in the fast path and the slow path.
Generally speaking, compilers don't try do deduplicate code that was written by the programmer, so they can't simplify the nearly-divisionless algorithm very much when the limit is constant.
Two points occurred to me:
when the limit is constant, the reject threshold (3) can be calculated at compile time
when the division is free, there's no need to avoid it using (4)
These observations suggested that when the limit is constant, the function for random numbers less than a limit should be written:
static inline uint32_t
pcg32_rand_const(pcg32_t *rng, uint32_t limit) {
uint32_t reject = -limit % limit;
uint64_t sample;
do sample = (uint64_t)pcg32_random(rng) * (uint64_t)limit;
while ((uint32_t)(sample) < reject);
return ((uint32_t)(sample >> 32));
}
This has only one call to pcg32_random(), saving space as I wanted,
and the compiler is able to eliminate the loop automatically when the
limit is a power of two. The loop is smaller than a call to an
out-of-line slow path function, so it's better all round than the code
I wrote last year.
As before it's possible to automatically choose the
constantly-divisionless or nearly-divisionless algorithms depending on
whether the limit is a compile-time constant or run-time variable,
using arcane C tricks or GNU C
__builtin_constant_p().
I have been idly wondering how to do something similar in other languages.
Rust isn't very keen on automatic specialization, but it has a reasonable alternative. The thing to avoid is passing a runtime variable to the constantly-divisionless algorithm, because then it becomes never-divisionless. Rust has a much richer notion of compile-time constants than C, so it's possible to write a method like the follwing, which can't be misused:
pub fn upto<const LIMIT: u32>(&mut self) -> u32 {
let reject = LIMIT.wrapping_neg().wrapping_rem(LIMIT);
loop {
let (lo, hi) = self.get_u32().embiggening_mul(LIMIT);
if lo < reject {
continue;
} else {
return hi;
}
}
}
assert!(rng.upto::<42>() < 42);
(embiggening_mul is my stable replacement for the unstable widening_mul API.)
This is a nugatory optimization, but there are more interesting cases
where it makes sense to choose a different implementation for constant
or variable arguments -- that it, the constant case isn't simply a
constant-folded or partially-evaluated version of the variable case.
Regular expressions might be lex-style or pcre-style, for example.
It's a curious question of language design whether it should be
possible to write a library that provides a uniform API that
automatically chooses constant or variable implementations, or whether
the user of the library must make the choice explicit.
Maybe I should learn some Zig to see how its comptime works.
https://dotat.at/@/2025-02-13-pcg32-simd.html
One of the neat things about the PCG random number generator by Melissa O'Neill is its use of instruction-level parallelism: the PCG state update can run in parallel with its output permutation.
However, PCG only has a limited amount of ILP, about 3 instructions. Its overall speed is limited by the rate at which a CPU can run a sequence where the output of one multiply-add feeds into the next multiply-add.
... Or is it?
With some linear algebra and some AVX512, I can generate random numbers from a single instance of pcg32 at 200 Gbit/s on a single core. This is the same sequence of random numbers generated in the same order as normal pcg32, but more than 4x faster.
You can look at the benchmark in my pcg-dxsm repository.
( Read more... )
https://dotat.at/@/2024-12-30-ioccc.html
The International Obfuscated C Code Contest has a newly revamped web site, and the Judges have announced the 28th contest, to coincide with its 40th anniversary. (Or 41st?)
The Judges have also updated the archive of past winners so that as many of them as possible work on modern systems. Accordingly, I took a look at my 1998 winner to see how much damage time hath wrought.
( Read more... )
https://dotat.at/@/2024-12-05-nsnotifyd-2-3-released.html
D'oh, I lost track of a bug report that should have been fixed in
nsnotifyd-2.2. Thus, hot on the heels of the previous release,
here's nsnotifyd-2.3. Sorry for causing extra work to
my uncountably many users!
The nsnotifyd daemon monitors a set of DNS zones and runs a command
when any of them change. It listens for DNS NOTIFY messages so it can
respond to changes promptly. It also uses each zone's SOA refresh and
retry parameters to poll for updates if nsnotifyd does not receive
NOTIFY messages more frequently. It comes with a client program
nsnotify for sending notify messages.
This nsnotifyd-2.3 release includes some bug fixes:
When nsnotifyd receives a SIGINT or SIGTERM while running the
command, it failed to handle it correctly. Now it exits promptly.
Many thanks to Athanasius for reporting the bug!
Miscellaneous minor code cleanup and compiler warning suppression.
Thanks also to Dan Langille who sent me a lovely appreciation:
Now that I think of it, nsnotifyd is in my favorite group of software. That group is software I forget I'm running, because they just run and do the work. For years. I haven't touched, modified, or configured nsnotifyd and it just keeps doing the job.
https://dotat.at/@/2024-11-28-nsnotifyd-2-2-released.html
I have made
a new release of nsnotifyd,
a tiny DNS server that just listens for NOTIFY messages
and runs a script when one of your zones changes.
This nsnotifyd-2.2 release includes a new feature:
nsnotify can now send NOTIFY messages from a specific source addressThanks to Adam Augustine for the suggestion. I like receiving messages that say things like,
Thanks for making this useful tool available for free.
https://dotat.at/@/2024-11-24-petnames.html
Recently the Spritely Institute published an introduction to Petnames, A humane approach to secure, decentralized naming.
I have long been a fan of petnames, and graph naming systems in general. I first learned about them in the context of Mark Miller's E programming language which was a distributed object capability system on the JVM. I gather Spritely are working on something similar, but with a more webby lisp/scheme flavour – and in fact Mark Miller is the second author on this article.
An interesting thing that the article sort of hints at is that these kinds of systems have a fairly smooth range of operating points from decentralized petnames all the way to centralized globally unique names. Zooko’s triangle is actually more like a fan when the "human friendly" point is fixed: there’s an arc describing the tradeoffs, from personal through local to global.
As a first step away from petnames, I like to use the term "nickname" for nearby instances of what they call "edge names" in the article: a nickname is not as personal as a petname, it’s a name you share with others.
A bit further along the arc is the article’s example of the "bizdir" local business directory. It's a trusted (and hopefully trustworthy) naming authority, but in a more local / federated fashion rather than centralized.
How can a petname system function at the global+centralized point, so it could replace the DNS? It needs to pass the "billboard test": I type in a name I see on a billboard and I get to the right place. (It might be a multipart name like a postal address or DNS name, with an extra "edge name" or two to provide enough disambiguating context.)
I imagine that an operating system supplier might provide a few preconfigured petnames (it probably includes its own petname so the software can update itself securely), a lot like its preconfigured PKIX CA certificates. These petnames would refer to orgs like the "bizdir", or Verisign, or Nominet, that act as nickname registries. Your collection of petnames is in effect your personal root zone, and the preconfigured petnames are in effect the default TLDs.
When I was thinking about how a decentralized graph naming system could be made user-friendly and able to pass the billboard test I realised that there are organizational structures that are hard to avoid. I expect there would inevitably be something like the CA/Browser forum to mediate between OS suppliers and nickname registries: a petname ICANN.
I wrote an older iteration of these ideas over a decade ago. Those notes suffer from too many DNS brainworms, but looking back, there's some curious anti-DNS discussion. How might it be useful to be able to reach a name by multiple paths? Could you use that for attestation? What might it look like to have a shared context for names that is not global but is national or regional or local?
https://dotat.at/@/2024-11-06-getopt.html
The other day I learned about the Rust crate lexopt which describes itself as,
A pathologically simple command line argument parser.
Most argument parsers are declarative: you tell them what to parse, and they do it. This one provides you with a stream of options and values and lets you figure out the rest.
For "pathologically simple" I still rather like getopt(3) despite its lack of support for long options. Aaron S Cohen wrote getopt in around 1979, and it was released into the public domain by AT&T in 1985. A very useful 50-ish lines of code! It still has almost everything required by POSIX nearly four decades later.
But the description of lexopt made me think getopt() could be
simpler. The insight is that the string of options that you have to
pass to getopt() is redundant with respect to the code that deals
with the return values from getopt(). What if you just get rid of
the options string?
I thought I would try it. Turns out, not much is lost in getting rid of the options string, and a few things are gained.
My new code is half the size or less of getopt(), and has more
functionality. I'm going to show how how this was done, because it's
short (ish), not because it is interesting. Then I'll try to tease out
a lesson or two.
( Read more... )
https://dotat.at/@/2024-10-22-tmp.html
I commented on Lobsters that /tmp is usually a bad idea,
which caused some surprise. I suppose /tmp security bugs were common
in the 1990s when I was learning Unix, but they are pretty rare now so
I can see why less grizzled hackers might not be familiar with the
problems.
I guess that's some kind of success, but sadly the fixes have left
behind a lot of scar tissue because they didn't address the underlying
problem: /tmp should not exist.
It’s a bad idea because it’s shared global mutable state that crosses security boundaries. There’s a ton of complexity at all levels of unix (filesystems, kernel APIs, libc, shell, admin scripts) that only exists as a workaround for the dangers caused by making
/tmpshared.
( Read more... )
https://dotat.at/@/2024-10-01-getentropy.html
A couple of notable things have happened in recent months:
There is a new edition of POSIX for 2024. There's lots of good stuff in it, but today I am writing about getentropy() which is the first officially standardized POSIX API for getting cryptographically secure random numbers.
On Linux the getentropy(3) function is based on the
getrandom(2) system call. In Linux 6.11 there is
a new vDSO call, vgetrandom(), that makes it possible
to implement getentropy() entirely in userland, which should
make it significantly faster.
UUID v4 and v7 are great examples of the need for high performance secure random numbers: you don't want the performance of your database inserts to be limited by your random number generator! Another example is DNS source port and query ID randomization which help protect DNS resolvers against forged answers.
I was inspired to play with getentropy() by a blog post about getting
a few secure random bytes in PostgreSQL without pgcrypto:
it struck me that PostgreSQL doesn't use getentropy(), and I thought
it might be fun (and possibly even useful!) to add support for it.
I learned a few things along the way!
( Read more... )
https://dotat.at/@/2024-08-30-gcra.html
Yesterday I read an article describing the GCRA rate limiting algorithm. I thought it was really interesting, but I wasn't entirely satisfied with Brandur's explanation, and the Wikipedia articles on leaky buckets and GCRA are terrible, so here's my version.
GCRA is the "generic cell rate algorithm", a rate-limiting algorithm that came from ATM. GCRA does the same job as the better-known leaky bucket algorithm, but using half the storage and with much less code.
GCRA only stores one time stamp per sender, whereas leaky buckets need to store a time stamp and a quota.
GCRA needs less arithmetic, and makes it trivial to tell a client how long it should wait before the next request is permitted.
( Read more... )
https://dotat.at/@/2024-08-02-turing-c.html
Yesterday there was some discussion on the Orange Site about whether or not C is Turing complete. The consensus in the StackOverflow question is,
no, because the C abstract machine is a (large) finite state machine,
or maybe yes, if you believe that unaddressable local variables can exist outside the finite address space.
My answer is definitely yes, if you include the standard IO library.
And using IO is much closer to Turing's original model of a finite state machine working on unbounded storage.
( Read more... )
https://dotat.at/@/2024-07-31-tolower-small.html
I'm pleased that so many people enjoyed my previous blog post on tolower() with AVX-512. Thanks for all the great comments and discussion!
One aspect that needed more work was examining the performance for small strings. The previous blog post had a graph for strings up to about 1000 bytes long, mainly because it illustrated some curious behaviour -- but that distracted me from what I really care about, which is strings up to about 100 bytes long, 10x smaller.
Eventually I managed to get some numbers that I think are plausible.
( Read more... )
https://dotat.at/@/2024-07-28-tolower-avx512.html
A couple of years ago I wrote about tolower() in bulk at speed using SWAR tricks. A couple of days ago I was interested by Olivier Giniaux's article about unsafe read beyond of death, an optimization for handling small strings with SIMD instructions, for a fast hash function written in Rust.
I've long been annoyed that SIMD instructions can easily eat short strings whole, but it's irritatingly difficult to transfer short strings between memory and vector registers. Oliver's post caught my eye because it seemed like a fun way to avoid the problem, at least for loads. (Stores remain awkward!)
Actually, to be frank, Olivier nerdsniped me.
Reading more around the topic, I learned that some SIMD instruction sets do, in fact, have useful masked loads and stores that are suitable for string processing, that is, they have byte granularity. They are:
ARM SVE, which is available on recent big-ARM Neoverse cores, such as Amazon Graviton, but not Apple Silicon.
AVX-512-BW, the bytes and words extension, which is available on recent AMD Zen processors. AVX-512 is a complicated mess of extensions that might or might not be available; support on Intel is particularly random.
I have an AMD Zen 4 box, so I thought I would try a little AVX-512-BW.
Using the Intel intrinsics guide I wrote a basic tolower()
function that can munch 64 bytes at once.
Top tip: You can use * as a wildcard in the search box, so I made
heavy use of mm512*epi8 to find byte-wise AVX-512 functions (epi8
is an obscure alias for byte).
First, we fill a few registers with 64 copies of some handy bytes.
We need the letters A and Z:
__m512i A = _mm512_set1_epi8('A');
__m512i Z = _mm512_set1_epi8('Z');
We need a number to add to uppercase letters to make them lowercase:
__m512i to_upper = _mm512_set1_epi8('a' - 'A');
We compare our input characters c with A and Z. The result of each
comparison is a 64 bit mask which has bits set for the bytes where
the comparison is true:
__mmask64 ge_A = _mm512_cmpge_epi8_mask(c, A);
__mmask64 le_Z = _mm512_cmple_epi8_mask(c, Z);
If it's greater than or equal to A, and less than or equal to Z,
then it is upper case. (AVX mask registers have names beginning with
k.)
__mmask64 is_upper = _kand_mask64(ge_A, le_Z);
Finally, we do a masked add. We pass c twice: bytes from the first
c are copied to the result when is_uppper is false, and when
is_upper is true the result is c + to_upper.
return _mm512_mask_add_epi8(c, is_upper, c, to_upper);
The tolower64() kernel in the previous section needs to be wrapped
up in more convenient functions such as copying a string while
converting it to lower case.
For long strings, the bulk of the work uses unaligned vector load and store instructions:
__m512i src_vec = _mm512_loadu_epi8(src_ptr);
__m512i dst_vec = tolower64(src_vec);
_mm512_storeu_epi8(dst_ptr, dst_vec);
Small strings and the stub end of long strings use masked unaligned loads and stores. This is the magic! This is the reason I wrote this blog post!
The mask has its lowest len bits set (its first len bits in
little-endian order). I wrote these two lines with perhaps more
ceremony than required, but I thought it was helpful to indicate that
the mask is not any old 64 bit integer: it has to be loaded into one
of the SIMD unit's mask registers.
uint64_t len_bits = (~0ULL) >> (64 - len);
__mmask64 len_mask = _cvtu64_mask64(len_bits);
The load and store look fairly similar to the full-width versions, but
with the mask stuff added. The z in maskz means zero the
destination register when the mask is clear, as opposed to copying
from another register (like in mask_add above).
__m512i src_vec = _mm512_maskz_loadu_epi8(len_mask, src_ptr);
__m512i dst_vec = tolower64(src_vec);
_mm512_mask_storeu_epi8(dst_ptr, len_mask, dst_vec);
That's the essence of it: you can see the complete version of
copytolower64() in my git repository.
To see how well it works, I benchmarked several similar functions. Here's a chart of the results, compiled with clang 16 on Debian 11, and run on an AMD Ryzen 9 7950X.

The pink [tolower64][] line is the code described in this blog post.
It is consistently near the fastest of all the functions under
test. (It drops a little at 65 bytes long, where it spills into a
second vector.)
The green [copybytes64][] line is a version of memcpy using
AVX-512 in a similar manner to tolower64. It is (maybe
surprisingly) not much faster. I had to compile copybytes64 with
Clang 11 because more recent versions are able to recognise what
it does and rewrite it completely.
The orange [copybytes1][] line is a byte-by-byte version of memcpy
again compiled using Clang 11. It illustrates that Clang 11 had
relatively poor autovectorizer heuristics and was pretty bad for
the last less-than-256-bytes of a string.
The very slow red [tolower][] line calls the standard
tolower() from <ctype.h> to provided a baseline.
The purple [tolower1][] line is a simple byte-by-byte version of
tolower() compiled with Clang 16. It shows that Clang 16 has a
much better autovectorizer than Clang 11, but it is slower and
much more complicated than my
hand-written version.
The brown [tolower8][] line is the SWAR tolower() from my
previous blog post. Clang valiantly tries to autovectorize
it, but the result is not great because the function is too
complicated. (It has the Clang-11-style 256-byte performance
cliffs despite being compiled with Clang 16.)
The blue memcpy line calls glibc's memcpy. There's something
curious going on here: it starts off fast but drops off to about
half the speed of copybytes64. Dunno why!
So, AVX-512-BW is very nice indeed for working with strings, especially short strings. On Zen 4 it's very fast, and the intrinsic functions are reasonably easy to use.
The most notable thing is AVX-512-BW's smooth performance: there's very little sign of the performance troughs that the autovectorizer suffers from as it shifts to scalar code for the scrag ends of strings.
I don't have convenient access to an ARM box with SVE support, so I have not investigated it in detail. It'll be interesting to see how well SVE works for short strings.
I would like both of these instruction set extensions to be much more widely available. They should improve the performance of string handling tremendously.
https://dotat.at/@/2024-07-18-semaphores.html
Semaphores are one of the oldest concurrency primitives in computing, invented over 60 years ago. They are weird: usually the only numbers of concurrent processes we care about are zero, one, or many – but semaphores deal with those fussy finite numbers in between.
Yesterday I was writing code that needed to control the number of concurrent operating system processes that it spawned so that it didn't overwhelm the computer. One of those rare situations when a semaphore is just the thing!
A Golang channel has a buffer size – a number of free slots – which corresponds to the initial value of the semaphore. We don't care about the values carried by the channel: any type will do.
var semaphore := make(chan any, MAXPROCS)
The acquire operation uses up a slot in the channel. It is
traditionally called P(), and described as decrementing the value of
the semaphore, i.e. decrementing the number of free slots in the
channel. When the channel is full this will block, waiting for another
goroutine to release the semaphore.
func acquire() {
semaphore <- nil
}
The release operation, traditionally called V(), frees a slot in
the channel, incrementing the value of the semaphore.
func release() {
<-semaphore
}
That's it!
The GNU make -j parallel builds feature uses a semaphore in the
form of its jobserver protocol. Occasionally, other programs
support the jobserver protocol too, such as Cargo. BSD make -j
uses basically the same semaphore implementation, but is not
compatible with the GNU make jobserver protocol.
The make jobserver semaphore works in a similar manner to a Golang
channel semaphore, but:
instead of a channel, make uses a unix pipe;
because make can't control the amount of free space in a
pipe's buffer, the value of the semaphore is represented as the
amount of used space in the pipe's buffer;
the value of the semaphore can't be more than PIPE_BUF, to
ensure that release() will never block.
Here's a C-flavoured sketch of how it works. To create a semaphore and initialize its value, create a pipe and write that many characters to it, which are buffered in the kernel:
int fd[2];
pipe(fd);
char slots[MAXPROCS] = {0};
write(fd[1], slots, sizeof(slots));
To acquire a slot, read a character from the pipe. When the pipe is empty this will block, waiting for another process to release the semaphore.
char slot;
read(fd[0], &slot, 1);
To release a slot, the worker must write the same character back to the pipe:
write(fd[1], &slot, 1);
Error handling is left as an exercise for the reader.
If we need to wait for everything to finish, we don't need any extra machinery. We don't even need to know how many tasks are still running! It's enough to acquire all possible slots, which will block until the tasks have finished, then release all the slots again.
func wait() {
for range MAXPROCS {
acquire()
}
for range MAXPROCS {
release()
}
}
That's all for today! Happy hacking :-)
https://dotat.at/@/2024-06-25-lemire-inline.html
a blog post for international RNG day
Lemire's nearly-divisionless algorithm unbiased bounded random numbers has a fast path and a slow path. In the fast path it gets a random number, does a multiplication, and a comparison. In the rarely-taken slow path, it calculates a remainder (the division) and enters a rejection sampling loop.
When Lemire's algorithm is coupled to a small random number generator such as PCG, the fast path is just a handful of instructions. When performance matters, it makes sense to inline it. It makes less sense to inline the slow path, because that just makes it harder for the compiler to work on the hot code.
Lemire's algorithm is great when the limit is not a constant (such as during a Fisher-Yates shuffle) or when the limit is not a power of two. But when the limit is a constant power of two, it ought to be possible to eliminate the slow path entirely.
What are the options?
( Read more... )
https://dotat.at/@/2024-06-12-nsnotifyd-2-1-released.html
I have made
a new release of nsnotifyd,
a tiny DNS server that just listens for NOTIFY messages
and runs a script when one of your zones changes.
This nsnotifyd-2.1 release includes a few bugfixes:
. in domain names on the command lineMany thanks to Lars-Johann Liman, JP Mens, and Jonathan Hewlett for the bug reports.
I have also included a little dumpaxfr program, which I wrote when
fiddling around with binary wire format DNS zone transfers. I used the
nsnotifyd infrastructure as a short cut, though dumpaxfr doesn't
logically belong here. But it's part of the family, so I wrote a
dumpaxfr(1) man page and included it in this release.
I will be surprised if anyone else finds dumpaxfr useful!
https://dotat.at/@/2024-05-22-regpg.html
Yesterday I received a bug report for regpg, my program that safely stores server secrets encrypted with gpg so they can be commited to a git repository.
The bug was that I used the classic shell pipeline find | xargs grep
with the classic Unix "who would want spaces in filenames?!" flaw.
I have pushed a new release, regpg-1.12, containing the bug fix.
There's also a gendnskey subcommand which I used when doing my
algorithm rollovers a few years ago. (It's been a long time since the
last regpg release!) It's somewhat obsolete, now I know [how to use
dnssec-policy][dnssec-policy].
A bunch of minor compatibility issues have crept in, which mostly required fixing the tests to deal with changes in Ansible, OpenSSL, and GnuPG.
My most distressing discovery was that Mac OS crypt(3)
still supports only DES. Good grief.
https://dotat.at/@/2024-05-13-what-ident.html
There are a couple of version control commands that deserve wider
appreciation: SCCS what and RCS ident.
They allow you to find out what source a binary was built from,
without having to run it -- handy if it is a library!
( Read more... )
https://dotat.at/@/2024-05-11-dnssec-policy.html
Here are some notes on migrating a signed zone from BIND's old
auto-dnssec to its new dnssec-policy.
I have been procrastinating this migration for years, and I avoided
learning anything much about dnssec-policy until this month. I'm
writing this from the perspective of a DNS operator rather than a BIND
hacker.
( Read more... )
https://dotat.at/@/2024-05-08-dnssec-policy.html
Here are some notes about using BIND's new-ish dnssec-policy feature
to sign a DNS zone that is currently unsigned.
I am in the process of migrating my DNS zones from BIND's old
auto-dnssec to its new dnssec-policy, and writing a blog post
about it. These introductory sections grew big enough to be worth
pulling out into a separate article.
( Read more... )
https://dotat.at/@/2024-05-05-frontmatter.html
As is typical for static site generators, each page on my web site is generated from a file containing markdown with YAML frontmatter.
Neither markdown nor YAML are good. Markdown is very much the worse-is-better of markup languages; YAML, on the other hand, is more like better-is-worse. YAML has too many ways of expressing the same things, and the lack of redundancy in its syntax makes it difficult to detect mistakes before it is too late. YAML's specification is incomprehensible.
But they are both very convenient and popular, so I went with the flow.
( Read more... )
https://dotat.at/@/2024-05-02-sudo.html
My opinion is not mainstream, but I think if you really examine the practices and security processes that use and recommend sudo, the reasons for using it are mostly bullshit.
( Read more... )
https://dotat.at/@/2024-04-30-wireguard.html
Our net connection at home is not great: amongst its several misfeatures is a lack of IPv6. Yesterday I (at last!) got around to setting up a wireguard IPv6 VPN tunnel between my workstation and my Mythic Beasts virtual private server.
There were a few, um, learning opportunities.
( Read more... )
https://dotat.at/@/2024-03-27-link-log.html
After an extremely long hiatus, I have resurrected my link log.
As well as its web page, https://dotat.at/:/, my link log is shared via:
The Dreamwidth feed has not caught this afternoon's newly added links, so I am not sure if it is actually working...
There is a lengthy backlog of links to be shared, which will be added to the public log a few times each day.
The backlog will be drained in a random order, but the link log's web page and atom feed are sorted in date order, so the most-recently shared link will usually not be the top link on the web page.
I might have to revise how the atom feed is implemented to avoid confusing feed readers, but this will do for now.
The code has been rewritten from scratch in Rust, alongside the static site generator that runs my blog. It's less of a disgusting hack than the ancient Perl link log that grew like some kind of fungus, but it still lacks a sensible database and the code is still substantially stringly typed. But, it works, which is the important thing.
edited to add ...
I've changed the atom feed so that newly-added entries have both a "published" date (which is the date displayed in the HTML, reflecting when I saved the link) plus an "updated" date indicating when it was later added to the public log.
I think this should make it a little more friendly to feed readers.
https://dotat.at/@/2024-03-26-iso-osi-usw.html
Back in December, George Michaelson posted an item on the APNIC blog titled "That OSI model refuses to die", in reaction to Robert Graham's "OSI Deprogrammer" published in September. I had discussed the OSI Deprogrammer on Lobsters, and George's blog post prompted me to write an email. He and I agreed that I should put it on my blog, but I did not get a round tuit until now...
( Read more... )
https://dotat.at/@/2024-02-05-joining-ellipses.html
In my previous entry I wrote about constructing a four-point egg, using curcular arcs that join where their tangents are at 45°. I wondered if I could do something similar with ellipses.
As before, I made an interactive ellipse workbench to experiment with the problem. I got something working, but I have questions...
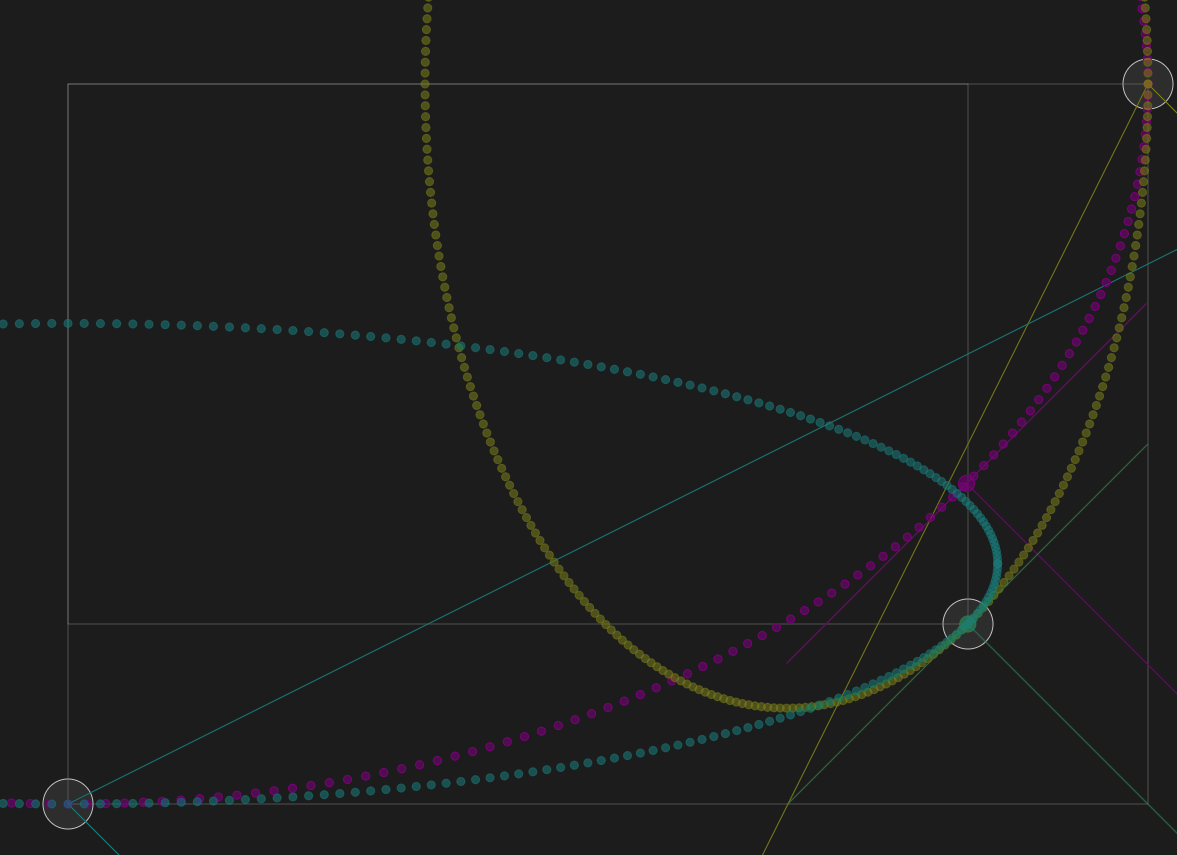
( Read more... )
https://dotat.at/@/2024-01-29-four-point-egg.html
For reasons beyond the scope of this entry, I have been investigating elliptical and ovoid shapes. The Wikipedia article for Moss's egg has a link to a tutorial on Euclidean Eggs by Freyja Hreinsdóttir which (amongst other things) describes how to construct the "four point egg". I think it is a nicer shape than Moss's egg.

Freyja's construction uses a straight edge and compasses in classical style, so it lacks dimensions. My version is on my blog, because Dreamwidth doesn't like my embedded SVG diagrams.
At first this construction seems fairly rigid, but some of its choices are more arbitrary than they might appear to be. I have made an interactive four-point egg so you can drag the points around and observe how its shape changes.
The Novelkeys Kailh Big Switch is a working MX-style mechanical keyboard switch, but 4x larger in every dimension.

I realised at the weekend that the Big Switch should fit nicely in a simple Lego enclosure. Because an MX-style switch is usually mounted in a 14x14 mm square plate coutout, at 4x larger the Big Switch would need a 56x56 mm mounting hole. Lego aficionados know that studs are arranged on an 8x8 mm grid; this means the Big Switch hole is exactly 7x7 studs. A plan was hatched and a prototype was made.
( Read more... )
https://dotat.at/@/2023-08-09-kbpcb.html
I'm a beginner at PCB design, or rather, I haven't made a PCB since I was at school 30 years ago, and a lot has changed since then! So my aim for Keybird69's PCB was to learn my way around the design, manufacturing, and assembly process.

( Read more... )
https://dotat.at/@/2023-08-06-ltbs.html
My Keybird69 uses LEGO in its enclosure, in an unconventional way.
Two years ago I planned to make a typical acrylic sandwich case for HHKBeeb, in the style of the BBC Micro's black and yellowish beige case. But that never happened because it was too hard to choose a place to get the acrylic cut so my spec.
My idea for using LEGO in a keyboard case was originally inspired by James Munns, who uses LEGO for mounting PCBs, including at least one keyboard.
Howver, I could not work out how to make a case that is nice and slender and into which the parts would fit. It is possible -- the KBDcraft Adam solves the problem nicely, and by all reports it's pretty good as a keyboard, not just a gimmick.
To make the PCB design easier, I am using a Waveshare RP2040-Tiny. It's more flexible than the usual dev boards used in custom keyboards because it has a separate daughterboard for the USB socket, but I had the devil of a time working out how to make it fit with LEGO.
Instead of using LEGO for the base, use FR-4, same as the switch mounting plate;
There isn't enough space for SNOT so I can't use LEGO studs to attach both the top and bottom of the case; why not use non-LEGO fasteners instead?
That will need through-holes, so maybe LEGO Technic beams will work?
Maybe the fasteners I got for the HHKBeeb case will work?

I wanted the fasteners for the HHKBeeb case to be as flat as possble; but acrylic does not work well with countersunk screws. Instead I looked for fasteners that protrude as little as possible.
For machine screws, I found the magic phrase is "ultra thin super flat wafer head". These typically protrude 1mm or less, whereas the more common button head or pan head protrude about 2mm or more.
I also discovered rivet nuts. They are designed to be inserted into a sheet metal panel and squashed so that they grip the panel firmly. But I just wanted them for their thin flange, less than 1mm.
The usual fasteners for a sandwich case are machine screws inserted top and bottom, with a standoff in between. But Keybird69 uses machine screws in the top and rivet nuts in the bottom.
I'm using M3 rivet nuts and machine screws. The outer diameter of the rivet nuts is 5mm; the inner diameter of the Technic holes is 4.8mm. Fortunately the beams are made from flexible ABS, so the rivet nuts can be squeezed in and make a firm press fit. They can be pushed out again with a LEGO Brick Separator.

Many dimensions of the keyboard are determined by the Cherry MX keyswitch de-facto standard.
The switch mounting plate must be about 1.5mm -- the standard PCB thickness of 1.6mm works fine.
The top of the PCB is 5mm below the top of the plate. The bottom of the PCB is also 5mm below the bottom of the plate because they are the same thickness. (Usually.)
The electronics are soldered to the bottom of the PCB.
A LEGO Technic beam is 8mm high (along the length of its holes).
The bodies of the switches and the PCB use 5mm of the beam height, leaving 3mm for the electronics. Plenty of space!
The height of the enclosure is 8 + 1.6 + 1.6 = 11.2 mm, which is pretty slender.
HHKBeeb's generic case uses 10mm acrylic so it's 2mm thicker, and the NightFox is about the same.

The Waveshare RP2040-Tiny daughterboard is problematic: its PCB is 1mm thick, and the USB-C receptacle is about 3.5mm high. It also has a couple of buttons for resetting or reflashing the RP2040, and they are a similar height.
I could not find a comfortable way to make space for it by cutting away part of the PCB to give it enough headroom. Then I had another brainwave!
I am not constrained by LEGO's rectilinear grid, so I could make space by angling the back of the case outwards slightly. The middle of the back of the case has the extra few milimetres needed for the USB daughterboard.
If you look closely at the picture above, behind the USB-C receptacle and the M2 nuts, you can see the whiteish top of one of the buttons, and behind that is the beige textured edge of the PCB.
(Also, I need to turn the beams round so that the injection moulding warts are not visible!)

LEGO studs use an 8mm grid. Keys are on a 3/4 in grid, or 19.05mm.
Keybird69 is 5 keys deep, which is slightly less than 12 LEGO studs.
It is 16 keys wide, which is slightly more than 38 LEGO studs. Three LEGO Technic 13 hole beams are 39 studs long.
The front and sides of Keybird69 are enclosed with 5 beams of 13 holes each, which stick out half a stud past the block of keys. They meet at the corners so that the tangent is 45° where the rounded ends of the beams are closest.
This arrangement leaves about 1mm clearance around the PCB. Spacious.
Technic beams are not as square in cross-section as you might expect. Their height (through the holes) is 8mm, whereas their width (across the holes) is 7.2mm. In Keybird69 I left 0.4mm gap between them -- I could have cut that down to 0.2mm without problems.

I used a 10mm radius of curvature for the corners. Apart from where the beams meet, the switch plate and base plate are very nicely flush with the beams.
I tried using a Sharpie permanent marker to blacken the edges of my Keybow 2040, but the ink did not stick very well. On Keybird69 I used an acrylic paint marker pen, which worked much better. Compare the raw fibreglass beige of the edges in the picture above to the black edges below.
One thing that probably isn't clear from the pictures is that the FR-4 plates have an unexpectedly lovely matte reflective quality. I think it might be because the black solder mask is not completely opaque so the layer of copper underneath gives it a bit of shine.
I am also getting some black 13 hole Technic beams to replace the dark grey ones, gotta make sure the dust shows up clearly on every possible surface!

https://dotat.at/@/2023-08-05-keycaps.html
There's plenty of material online about the bewildering variety of keycaps, eg, eg, but I learned a few things that surprised me when working on Keybird69.

I found out that the remaining stock of Matteo Spinelli's NightFox keyboards were being sold off cheap because of a manufacturing defect. I grabbed one to find out what it's like, because its "True Fox" layout is very similar to the unix69 layout I wanted.
My NightFox turned out to have about three or five unreliable keyswitches, which meant it was just about usable -- tho the double Ts and unexpected Js rapidly became annoying.
But it was usable enough that I was able to learn some useful things from it.
The black-on-grey keycaps look cool, but they are basically illegible. (The picture above exaggerates their albedo and contrast.) This is a problem for me, especially while I was switching from the HHKBeeb ECMA-23-ish layout to an ANSI-ish TrueFox-ish unix68 layout.
Fortunately I learned this before making the mistake of buying some fancy black-on-grey keycaps.
I had seen a few keycap sets with extra up arrows, which puzzled me (For example.) The NightFox came with an extra up arrow, and eventually I twigged that it makes the profile of the arrow cluster a bit nicer.
Usually, in a sculpted keycap profile (where each row of keycaps has a differently angled top surface) the bottom two rows have the same angle, sloping away from the typist. This means the up arrow key slopes away from the other arrows on the row below.
The extra up arrow keys typically match the tab row, which is flat or angled slightly towards the typist. This gives the arrow cluster a more dishy feeling.
Unfortunately the keycaps I ordered do not have extra up arrow keys with tab row angle as an option. I did not realise until after I ordered them that I could have got a similar effect by using a reversed down arrow as an up arrow -- it makes a sharper angle, but still feels nicer. So I'm using a reversed arrow key for Keybow69's up button and my up/down legends both point the same way.
Some keycap sets have multiple page up / page down / home / end keys with different row profiles so that people with 65% and 75% keyboards can rearrange the right column of keys. (For example.)
Instead of the superfluous navigation keys, I used the NightFox novelty keycaps on my keyboard. (You can see the ANY KEY, the cute fox logo, etc. in the picture above.) These all had a top row profile, and at first I thought this was an ugly compromise.
But it turns out that the difference in height between the right column and the main block of keys is really useful for helping to keep my fingers in the right places. It makes me less likely to accidentally warp a window when I intend to delete a character.

The mismatched angle of the up arrow key is similarly helpful. Matt3o added a gap next to the arrow keys in his True Fox design to make the arrow keys easier to locate, but I think that isn't necessary with an out-of-profile up arrow (which is also one of Matt3o's favourite features).
I previously thought I wanted a uniform keycap profile (e.g. DSA like the keycaps that came with my Keybow 2040) but these discoveries taught me a sculpted profile is more practical for the keyboard I was making.
Another research purchase was a grab bag of random surplus keycaps, which is about as useless as you might expect: hundreds of keycaps, but too many duplicates to populate a keyboard. (My Keybow 2040 now has a very colourful mixture of miscellaneous keycaps.) The grab bag I got was mostly SA profile, which is tall and steeply angled on the near and far rows. In their normal orientation, SA function keys would probably not work so well on the right column of my keyboard, making a shape like a warehouse roof. Maybe they would work when rotated 90°? Dunno.

One of my old beliefs remained: I still prefer spherical indentations in the tops of my keycaps. They are more cuddly around my fingertips than the more common cylindrical indentations.
Annoyingly, many of the newer sculpted spherical keycap sets are hard to get hold of: often the only places that have them in stock will not ship to the UK at an affordable price. (For example.) Also annoyingly, the cheaper keycap sets almost never have the extras needed for unix69 compatibility. Bah.
The black-on-grey NightFox keycaps are Cherry profile (cylindrical indentations, sculpted rows, very short), and the keycaps that WASD printed for my HHKBeeb are OEM profile (like Cherry profile but taller). The HHKBeeb doesn't have spherical keycaps because I don't know anywhere that will do affordable one-off prints other than OEM profile. I also have a set of TEX ADA keycaps (uniform rows, short) which have lovely deeply scooped spherical tops, tho I am not a fan of their Helvetica legends.
So instead of a set of DSA keycaps (DIN height, spherical top, uniform) as I originally planned, I got DSS keycaps (DIN height, spherical top, sculpted). I love the Gorton Modified legends on Signature Plastics keycaps: as a business they descend from Comptec who made most BBC Micro keycaps.
I think Matt3o's MTNU Susu keycaps are closer to my ideal, but I missed the group buy period and they have not been manufactured yet. And I wish they had an option for icons on the special keys instead of WORDS. I suspect the MTNU profile will become very popular, like Matt3o's previous MT3 profile, so there will be chances to get some in the future.
https://dotat.at/@/2023-08-04-unix69.html
A proper Unix keyboard layout must have escape next to 1 and control next to A.
Compared to the usual ANSI layout, backquote is displaced from its common position next to 1. But a proper Unix keyboard should cover the entire ASCII repertoire, 94 printing characters on 47 keys, plus space, in the main block of keys.
To make a place for backquote, we can move delete down a row so it is above return, and put backslash and backquote where delete was.
(Aside: the delete key emits the delete character, ASCII 127, and the return key emits the carriage return character, ASCII 13. That is why I don't call them backspace and enter.)
This produces a layout similar to the main key block of Sun Type 3, Happy Hacking, and True Fox keyboard layouts.
Personally, I prefer compact keyboards so I don't have to reach too far for the mouse, but I can't do without arrow keys. So a 65% keyboard size (5 rows, 16 keys wide) is ideal.
If you apply the Unix layout requirements to a typical ANSI 68-key 65% layout, you get a 69-key layout. I call it unix69. (1969 was also the year Unix started.)
http://www.keyboard-layout-editor.com/#/gists/2848ea7a272aa571d140694ff6bbe04c

I have arranged the bottom row modifiers for Emacs: there are left and right meta keys and a right ctrl key for one-handed navigation. Meta is what the USB HID spec calls the "GUI" key; it sometimes has a diamond icon legend. Like the HHKB, and like Unix workstations made by Apple and Sun, the meta keys are either side of the space bar.
There are left and right fn keys for things that don't have dedicated keys, e.g. fn+arrows for page up/page down, home, end. The rightmost column has user-programmable macro keys, which I use for window management.
http://www.keyboard-layout-editor.com/#/gists/6610c45b1c12f962e6cf564dc66f220b
ANSI 65% keyboards have caps lock where control should be.
They have an ugly oversized backslash and lack a good place for backquote.
The right column is usually wasted on fixed-function keys.
It's common for 65% keyboards to have 67 or 68 keys, the missing key making a gap between the modifiers and arrow keys on the bottom row. I prefer to have more rather than fewer modifier keys.
http://www.keyboard-layout-editor.com/#/gists/f1742e8e1384449ddbb7635d8c2a91a5
Matteo Spinelli's Whitefox / Nightfox "True Fox" layout has top 2 rows similar to unix69. It sometimes has backslash and backquote swapped.
Unfortunately it has caps lock where control should be. Its right column is wasted on fixed-function keys (though the keyboards are reprogrammable so it's mainly a keycap problem).
On the bottom row, True Fox has two modifers and a gap between space and arrows, whereas unix69 has three modifiers and no gap.
http://www.keyboard-layout-editor.com/#/gists/c654dc6b4c7e30411cad8626302e309f
The Happy hacking keyboard layout is OK for a 60% Unix layout. However it lacks a left fn key, and lacks space for full-size arrow keys, so I prefer a 65% layout.
https://dotat.at/graphics/keybird69.jpg
Owing to the difficulty of getting keycaps with exactly the legends I would like, the meta keys on my keybird69 are labelled super and the delete key is labelled backspace. I used F1 to F4 keycaps for the macro keys, tho they are programmed to generate F13 to F16 which are set up as Hammerspoon hot keys.
But otherwise keybird69 is a proper unix69 keyboard.
Another keyboard!
https://dotat.at/@/2023-08-04-keybird.html
A couple of years ago I made a BBC Micro tribute keyboard in the runup to the beeb's 40th anniversary. I called it HHKBeeb:

The HHKBeeb is made from:
I planned to make a beeb-style acrylic sandwich case, but it was too hard to choose a place to get the acrylic cut, so that never happened.
In practice I find 60% keyboards (like the Happy Hacking Keyboard) too small -- I need an arrow cluster. So I used the HHKBeeb with a Keybow 2040 macro pad to give me arrows and a few function keys for moving windows around.
My new keyboard is for a Finch and it has 69 keys, so it's called Keybird69. (I was surprised that this feeble pun has not already been used by any of the keyboards known to QMK or VIA!)

It is made from:
A combination of reasons:
I have been mildly obsessed with compact keyboards practically forever, but back in the 1990s there were no good options available to buy, so I made do without.
The first small keyboard I liked was the (now discontinued) HHKB Lite
2,
which has an arrow cluster unlike the pure HHKB. I have a couple of
these lurking in the Boxes Of Stuff in the corner. But I'm not a huge
fan of the limited modifiers, or the Topre key switches (they're a bit
mushy), or the styling of the HHKB case.
Correction: the HHKB Lite 2 did not actually use Topre switches.
I gradually used Macs more, and switched to using the Apple Aluminium keyboard - the model A1242 compact wired version, and the model A1314 wireless version. I also switched from a Kensington Expert Mouse trackball to an Apple Magic Trackpad.
But then Apple lost the plot with its input devices, so I thought I should plan to wean myself off. And in the mean time, the custom keyboard scene had flourished into a vibrant ecosystem of open source hardware and software.
So instead of relying on someone else to make a keyboard I like, I could make one myself! My own PCB and switch plate, designed for just the layout I want.
And with QMK open source firmware, I can make good use of the fn key that was so disappointingly unconfigurable on the HHKB and Apple keyboards.
I'm planning to write some more notes about various details of the design:
https://dotat.at/@/2023-06-23-random-more.html
I got some interesting comments about my previous notes on random floating point numbers on Lobsters, Dreamwidth, and from Pete Cawley on Twitter.
Here's an addendum about an alternative model of uniformity.
There are 2^62 double precision floats between 0.0 and 1.0, but as I described before under "the problem", they are not distributed uniformly: the smaller ones are much denser. Because of this, there are two ways to model a uniform distribution using floating point numbers.
Both algorithms in my previous note use a discrete model: the functions return one of 2^52 or 2^53 evenly spaced numbers.
You can also use a continuous model, where you imagine a uniformly random real number with unbounded precision, and return the closest floating point result. This can have better behaviour if you go on to transform the result to model different distrbutions (normal, poisson, exponential, etc.)
Taylor Campbell explains how to generate uniform random double-precision floating point numbers with source code. Allen Downey has an older description of generating pseudo-random floating-point values.
In practice, the probability of entering the arbitrary-precision loop in Campbell's code is vanishingly tiny, so with some small adjustments it can be omitted entirely. Marc Reynolds explains how to generate higher density uniform floats this way, and Pete Cawley has terse implementations that use one or two random integers per double. (Reynolds also has a note about adjusting the range and fenceposts of discrete random floating point numbers.)
https://dotat.at/@/2023-06-23-random-double.html
Here are a couple of algorithms for generating uniformly distributed
floating point numbers 0.0 <= n < 1.0 using an unbiased
random bit generator and IEEE 754 double precision arithmetic. Both of
them depend on details of how floating point numbers work, so before
getting into the algorithms I'll review IEEE 754.
The first algorithm uses bit hacking and type punning. The second uses a hexadecimal floating point literal. They are both fun and elegant in their own ways, but these days the second one is better.
( Read more... )
https://dotat.at/@/2023-06-21-pcg64-dxsm.html
Last week I was interested to read about the proposed math/rand/v2
for Golang's standard library. It mentioned a new-ish flavour
of PCG called DXSM which I had not previously encountered. This blog
post collects what I have learned about PCG64 DXSM. (I have not found
a good summary elsewhere.)
( Read more... )
Last week I was at the RIPE86 meeting in Rotterdam, so I have been spamming my blog with news about what I got up to while I was there. I was too lazy to cross-post here; I really should automate it!
Last weekend, there was a DNS Hackathon in which I successfully avoided working with BIND, learned some new tricks, and shared a lot of ideas, hints, and tips.
In the main RIPE meeting, I rashly offered to give a lightning talk called where does my computer get the time from? It was accepted for a slot on Friday morning, and I was very pleased with how well it was received :-) So I wrote a followup about things that did not make it into the talk.
https://dotat.at/@/2023-02-28-qp-bind.html
In 2021, I came up with a design for a new memory layout for a qp-trie, and I implemented a prototype of the design in NLnet Labs NSD (see my git repo or github).
Since I started work at ISC my main project has been to adapt the NSD prototype into a qp-trie for use in BIND. The ultimate aim is to replace BIND's red-black tree database, its in-memory store of DNS records.
Yesterday I merged the core qp-trie implementation into BIND so it's a good time to write some blog notes about it.
The core of the design is still close to what I sketched in 2021 and implemented in NSD, so these notes are mostly about what's different, and the mistakes I made along the way...
( Read more... )
https://dotat.at/@/2023-02-12-longjmp.html
Chris Wellons posted a good review of why large chunks of the C
library are terrible,
especially if you are coding on Windows - good fun if you like staring
into the abyss. He followed up with let's write a
setjmp which is fun in a
more positive way. I was also pleased to learn about
__builtin_longjmp! There's a small aside in this article about the
signal mask, which skates past another horrible abyss - which might
even make it sensible to DIY longjmp.
Some of the nastiness can be seen in the POSIX rationale for
sigsetjmp which says that on BSD-like systems, setjmp and
_setjmp correspond to sigsetjmp and setjmp on System V Unixes.
The effect is that setjmp might or might not involve a system call
to adjust the signal mask. The syscall overhead might be OK for
exceptional error recovery, such as Chris's arena out of memory
example, but it's likely to be more troublesome if you are
implementing coroutines.
But why would they need to mess with the signal mask? Well, if you are
using BSD-style signals or you are using sigaction correctly, a
signal handler will run with its signal masked. If you decide to
longjmp out of the handler, you also need to take care to unmask the
signal. On BSD-like systems, longjmp does that for you.
The problem is that longjmp out of a signal handler is basically
impossible to do correctly. (There's a whole flamewar in the wg14
committee documents on this subject.) So this is another example of
libc being optimized for the unusual, broken case at the cost of the
typical case.
The other day, Paul McKenney posted an article on LiveJournal about different flavours of RCU, prompted by a question about couple of Rust RCU crates. (There are a few comments about it on LWN.)
McKenney goes on to propose an RCU classification system based on the API an implementation provides to its users. (I am curious that the criteria do not involve how RCU works.)
Here's how I would answer the questions for QSBR in BIND:
Are there explicit RCU read-side markers?
No, it relies on libuv callbacks to bound the lifetime of a
read-side critical section.
Are grace periods computed automatically?
Yes. There is an internal isc__qsbr_quiescent_state() function,
but that mainly exists to separate the QSBR code from the event
loop manager, and for testing purposes, not for use by
higher-level code.
Are there synchronous grace-period-wait APIs?
No. (Because they led me astray when designing a data structure to use RCU.)
Are there asynchronous grace-period-wait APIs?
Yes, but instead of one-shot call_rcu(), a subsystem (such as
the qp-trie code) registers a permanent callback
(isc_qsbr_register()), and notifies the QSBR when there is work
for the callback to do (isc_qsbr_activate()). This avoids having
to allocate a thunk on every modification, and it automatically
coalesces reclamation work.
If so, are there callback-wait APIs?
No. At the moment, final cleanup work is tied to event loop teardown.
Are there polled grace-period-wait APIs?
No.
Are there multiple grace-period domains?
One per event loop manager, and there's only one loopmgr.
https://dotat.at/@/2023-01-24-qp-bench.html
Previously, I wrote about implementing safe memory reclamation for my qp-trie code in BIND. I have now got it working with a refactored qp-trie that has been changed to support asynchronous memory reclamation - working to the point where I can run some benchmarks to compare the performance of the old and new versions.
( Read more... )
{kind=link}
.jpg){kind=link}
{kind=link}